-
Southwark Cyclists reject these proposals.
-
Southwark Council’s proposals for Camberwell Green alterations do nothing to address serious and worsening safety issues for cyclists.
-
These largely cosmetic alterations also miss several opportunities to substantially improve crossing times and safety for pedestrians.
-
These proposals assume increasing traffic flow when TfL’s own figures show car ownership, use, and miles travelled are all decreasing in this part of London. The Council’s own figures and transport policy forecast a rise in cycle numbers.
-
We urge Southwark Council and Transport for London to reconsider their approach to this key junction and the Camberwell Green area. Space for cycling at the junction and/or a cycle bypass are feasible alternatives to their proposals.
Sensible Alternatives
A number of sensible alternatives exist which could be built in a similar amount of time and disruption, and would greatly improve the safety and convenience of the area for cyclists and pedestrians alike:

- Six lanes of traffic at Camberwell Green – on Denmark Hill looking south.

The public environment. Firstly, even the council recognise that the Green itself is a retail and services destination. Thousands of local people use the Green every day for shopping, the library, pharmacy, clinic and courts. But the public environment on Camberwell Church Street and Denmark Hill (outside Butterfly Walk) is intimidating for pedestrians and cyclists alike, with trucks and coaches hurtling down six lanes of traffic at 30mph+, as this picture shows. It’s hard to cross and no wonder so many people prefer to drive short distances to these shops. The proposal does nothing to improve the environment – although the pavement itself will get some expensive new stone, nothing will be done to make it easier or more inviting to get to the Green by bike or on foot, or cross the road once you’re there. Southwark Cyclists propose the town centre, one of the historic local greens of South London, be more imaginatively redesigned as a retail and services destination where pedestrians and cyclists come first. This can be done while maintaining traffic capacity, but calming it.
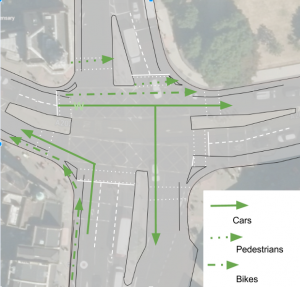
- Space for Cycling at the crossroads. Although both Southwark Council and Transport for London are committed to decreasing cycle and pedestrian deaths and injuries on the roads, and increasing numbers of cycling and walking trips in Southwark by 2020, the junction design Southwark Council propose is straight out of the 1980s – ‘stuff traffic through as quickly as possible, and hope nothing goes wrong’. In fact it’s barely different from the current layout here (one death already this year…) except that, incredibly, there are fewer cycle facilities than now. In conjunction with experts from another London borough and the London Cycling Campaign, Southwark Cyclists propose an alternative design for the green where pedestrians, cyclists and motor traffic all move separately. This layout will retains motor vehicle capacity, is safe for cyclists, and far more convenient for larger numbers of pedestrians. To read more, see our consultation response.

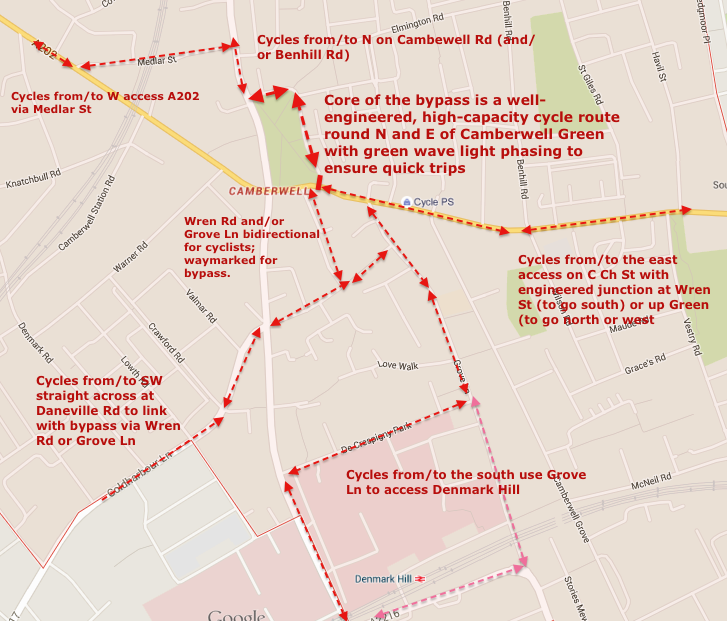
A bus hub – in Orpheus Street, not the high street. One of the council’s motivations for doing anything at all is the large numbers of pedestrians waiting for busses on the pavement outside the shopping centre. Often these spill out into the road; it’s unsafe and hard to get past with a pushchair or wheelchair. Instead of the council’s plans (which actually add hardly any space at all on the pavement in question, and do nothing to calm the traffic at all) we suggest several bus stops could be moved 10-20m down, into Orpheus Street, creating a local bus hub. With proper lighting and other features, this could also be a much safer place to wait, and would create additional retail or services frontages in Orpheus Street, which at the moment is a barren alley with just the art shop. Why move the bus stops at all? Well, moving them from the high street (Denmark Hill) would make the crossing simpler for pedestrians, make driving easier for cars (no busses cutting in and out suddenly), make cycling safer (by freeing space for a bike lane) and the environment far more pleasant for everyone.
Basically, there are several options, far better than the Council’s plans. Reject these plans today (Thurs 13th August closing date) and send them back to the drawing board!